Dynamic Load Balancing for a hp-adaptive Discontinuous Galerkin Wave Equation Solver via Spacing-Filling Curve and Advanced Data Structure¶
Abstract:¶
Scientific or engineering simulations of complex fluid flows, e.g., turbulent flow, often resort to high-order methods to obtain high resolutions. However, a large-scale, time-dependent, long-time simulation can be extremely computationally expensive. To achieve high resolution while maximizing the computational savings, we combine a high-order method – the discontinuous Galerkin spectral element method (DG-SEM), with parallel adaptive mesh refinement and coarsening (AMR) techniques and apply it to a two-dimensional wave equation solver. DG-SEM discretizes solution functions as weighted polynomial series. In this work, Legendre polynomials are chosen. With higher-order method and AMR techniques, a computational cost-efficient solver is formed.
Two types of refinements are invoked: h-refinement, where elements are split or merged, and p-refinement, where polynomial orders can be increased or decreased. To retain the spectral convergence on the non-conforming element interfaces caused by the hp-refinement, the mortar element method is adopted.
A hash table AMR technique is developed for the AMR data encoding and storing. It can be built independently on distributed memory systems. It provides high control of the mesh resolution and efficient data management operations. Results using this approach on the adaptive wave equation solver confirm that its memory usage remains low on up to 16,384 processors for a problem with over a million elements and 150 million degrees of freedom.
Dynamic load imbalance is incurred by the adaptivity of the program, which degrades the performance of the supercomputers. A space-filling curve (SFC) based repartitioning algorithm is implemented in this work. The algorithm is designed to execute quickly in parallel. Its low memory overhead is beneficial to distributed memory systems. Additionally, the high-quality repartitioning results successfully reduce the dynamic workload imbalance among the computational processors. The scalability of the load balancing algorithm is demonstrated on two different high-performance computing systems with up to 16,384 processors. The maximum memory scaling is up to 4,096 processors and no considerable memory growth is observed beyond the maximum scaling. High load balancing quality is demonstrated.
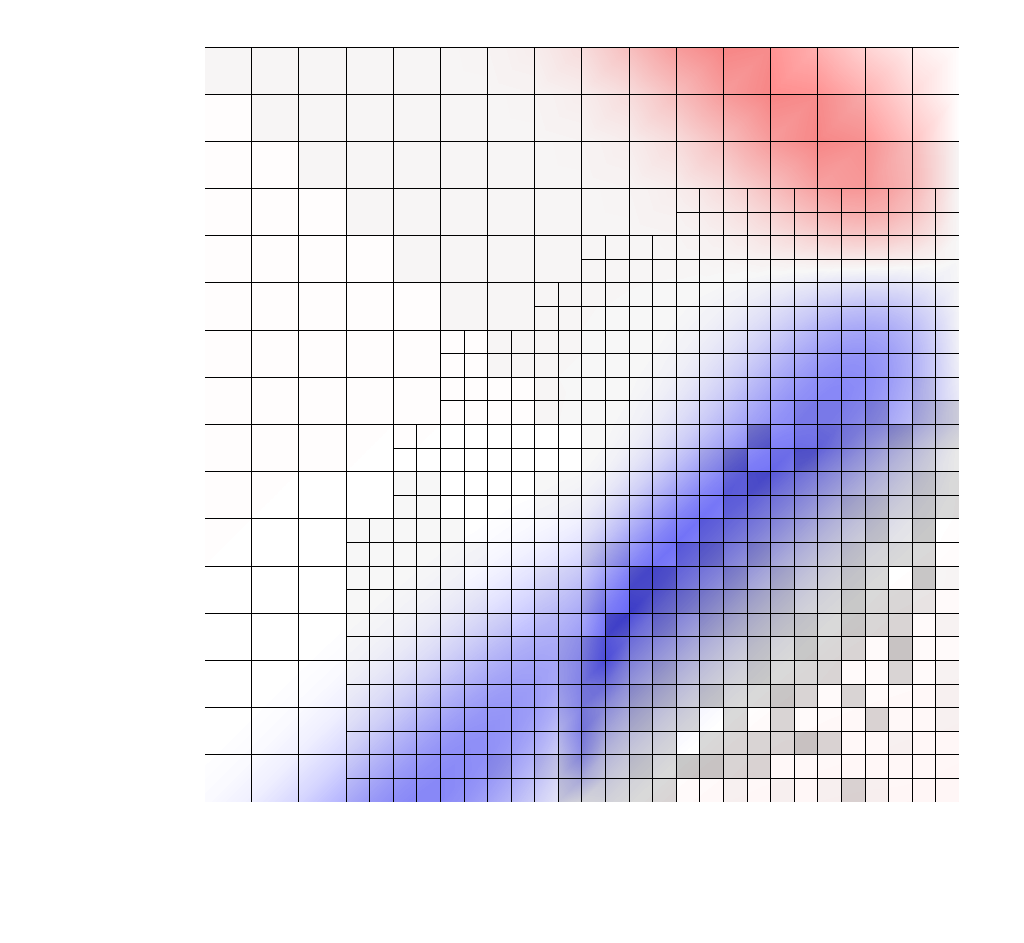
Fig 1. hp-refined mesh.¶ |
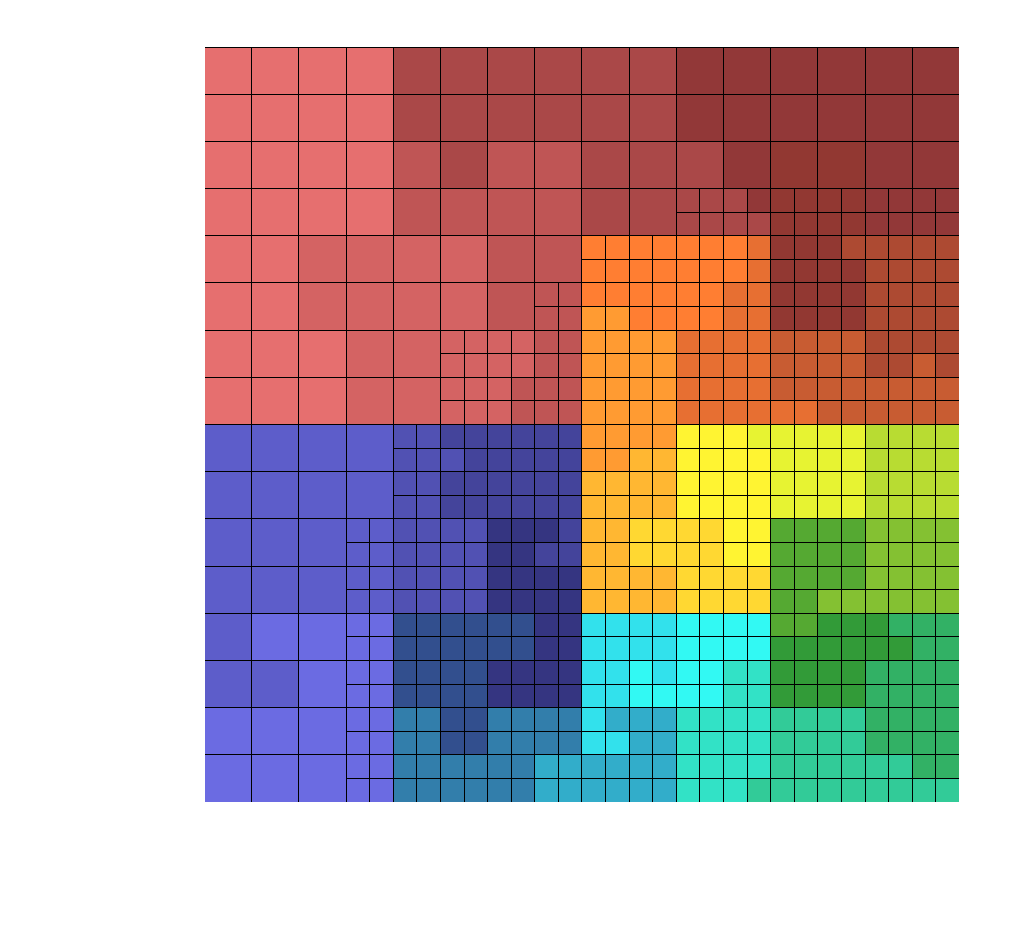
Fig 2. Repartitioning result (32 processors).¶ |
Using the hash table AMR and SFC-based repartitioning algorithm, we obtain speedup factors up to 8.46 over a range of processor numbers from 32 to 2048, which, in the long run, can reduce week-long computational wait-times to a matter of days.